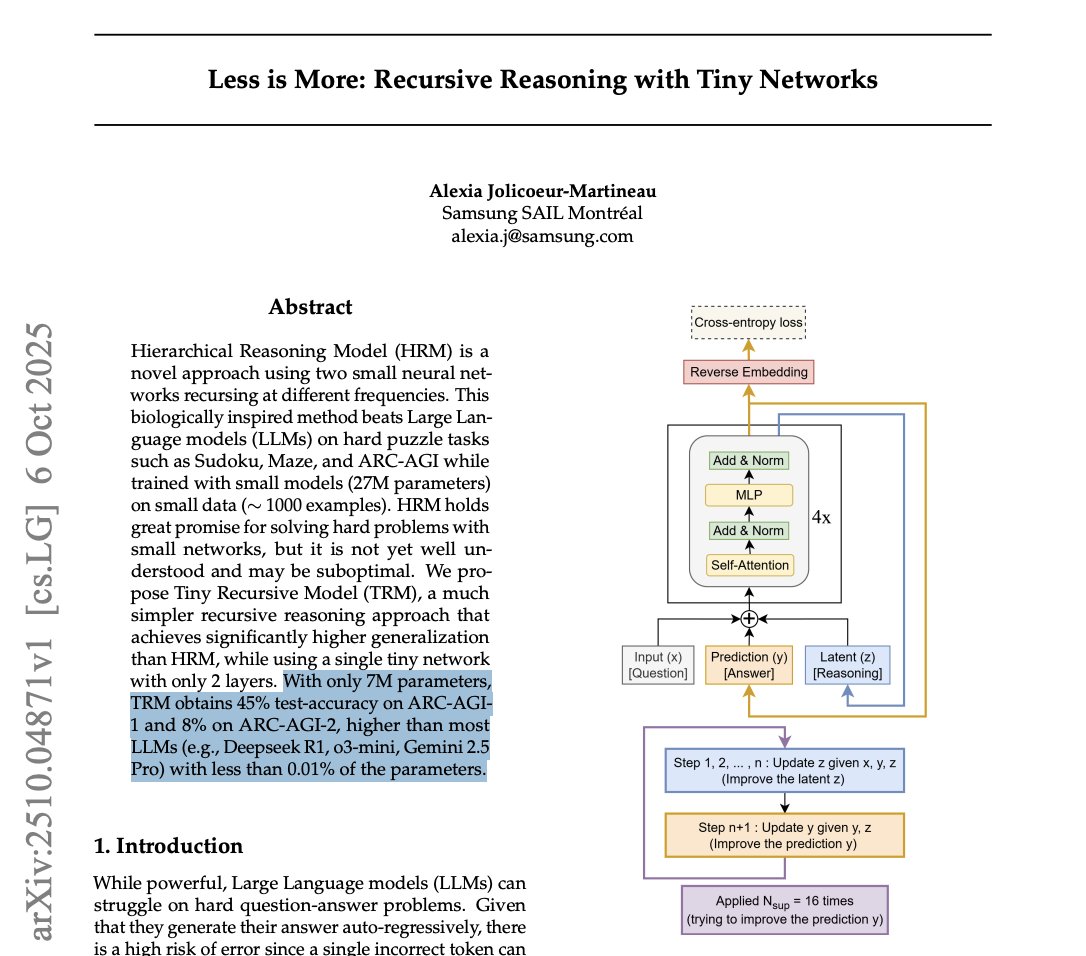
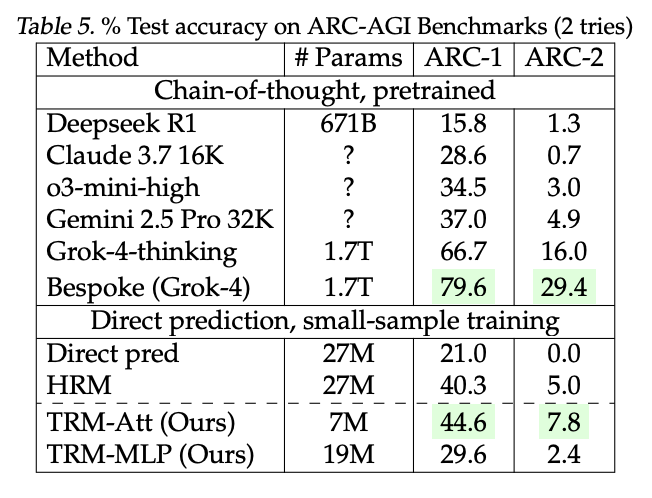
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It’s called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here’s how it works: 1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete “draft” of the solution. Think of this as its first rough guess. 2. Create a “Scratchpad”: It then creates a separate space for its internal thoughts, a latent reasoning “scratchpad.” This is where the real magic happens. 3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, “Does my logic hold up? Where are the errors?” 4. Revise the Answer: After this focused “thinking,” it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer. 5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution. Why this matters: Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost. Researchers: This is a major validation for neuro-symbolic ideas. The model’s ability to recursively “think” before “acting” demonstrates that architecture, not just scale, can be a primary driver of reasoning ability. Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere. This isn’t just scaling down; it’s a completely different, more deliberate way of solving problems.